
В прошлой статье мы осторожно познакомились с «кентаврами» — существами, часто очень волшебными, которые появляются из-за ошибок при создании единой клиентской базы. Разговор получился довольно поверхностным, мы не рассмотрели детали вблизи.
Исправляемся, начинаем цикл статей о поиске похожих клиентов, слиянии их данных, последующем обновлении и возможном разделении. Начнем с поиска дубликатов.
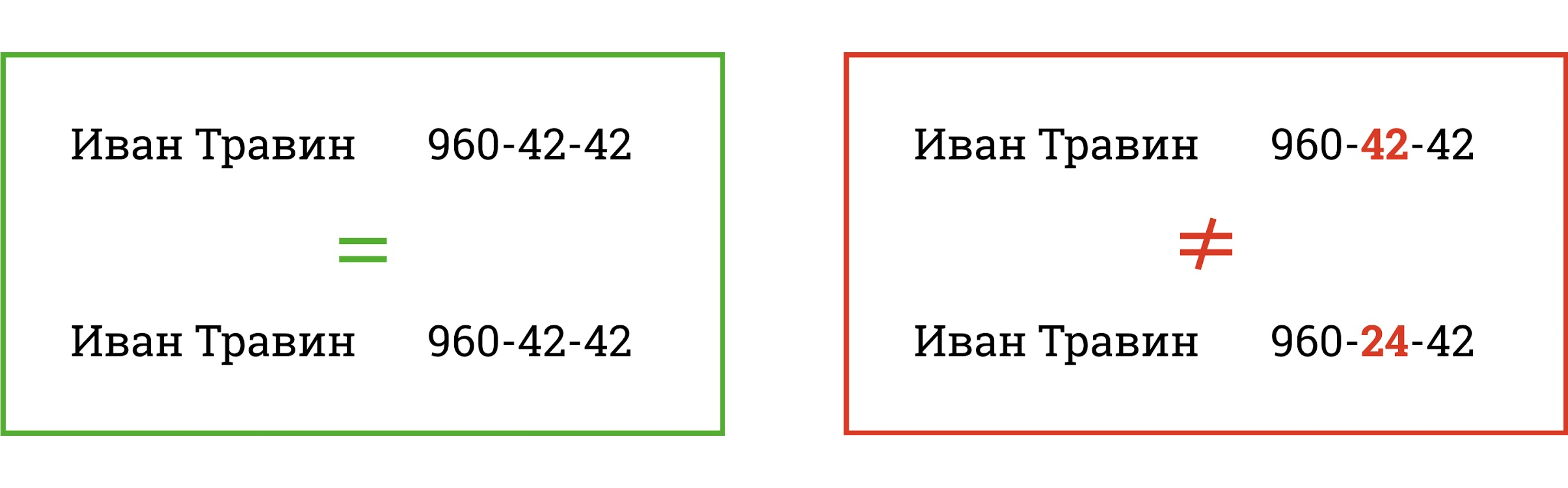
Знакомьтесь — Иван Травин
Иван Травин — обычный клиент обычного банка. Этот замечательный гражданин поможет нам разобраться с поиском дублей в клиентских базах.
Иван открыл в банке счет, получил кредитную карту и недавно отправил через сайт заявку на кредит наличными. Поскольку у господина Травина три продукта, банк хранит записи о нем в трех разных IT-системах.

Для простоты и наглядности представим: все, что известно банку об Иване — имя, фамилия и номер телефона без кода города.
И вот настал чудесный день: банк решил прибраться в клиентской базе, а для этого загрузил данные из всех источников в CDI-систему. Ее задача: собрать данные из разных баз в единые «золотые» карточки клиентов, а дубли удалить.
На этом этапе система должна решить, какие записи относятся к одним и тем же людям. Но как она это сделает?
Есть три главных подхода к поиску похожих карточек.
Жесткие правила
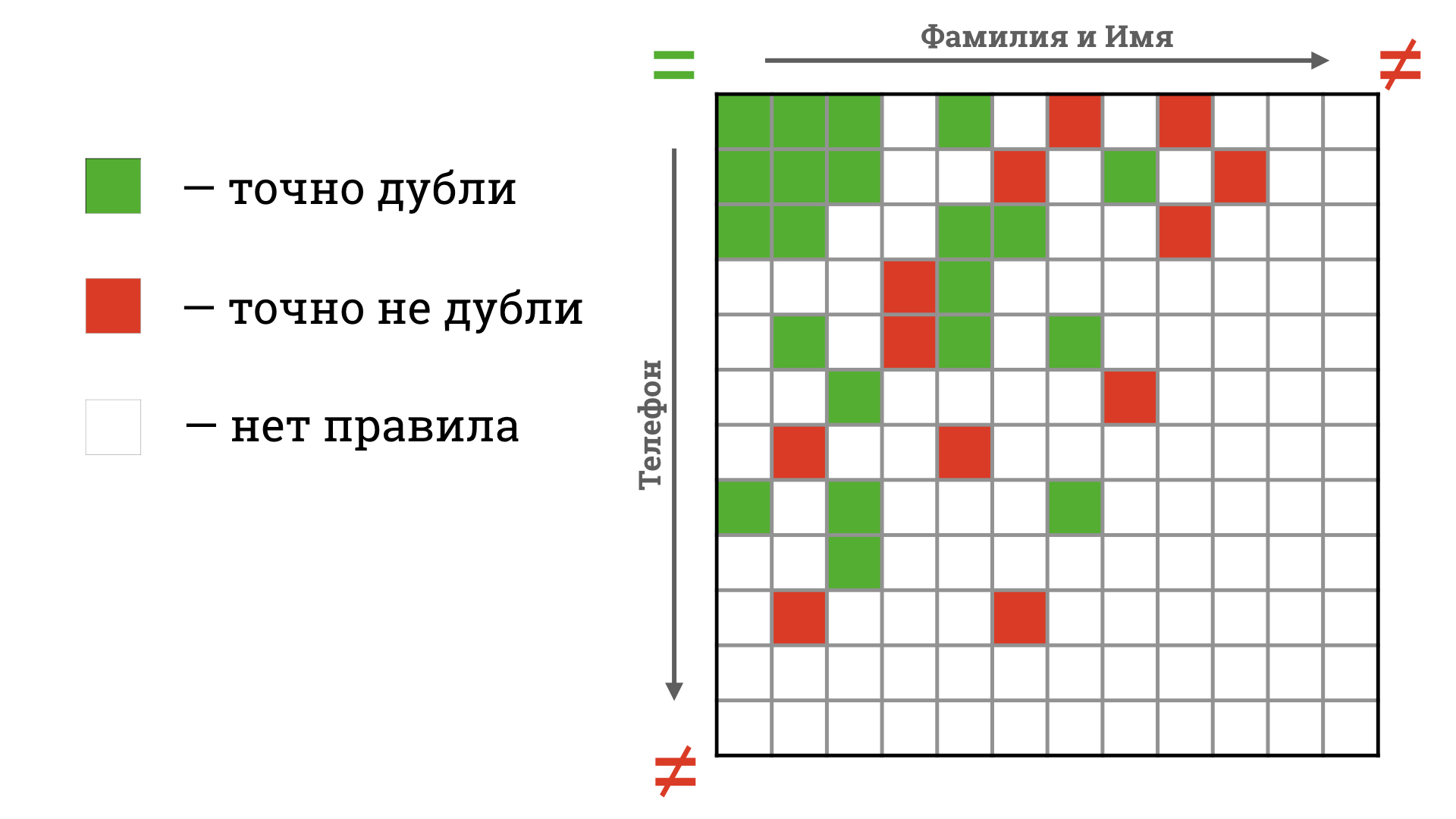
Самый простой вариант, который первым приходит в голову: если данные совпадают, карточки принадлежат одному человеку. Если нет — разным. Получается примерно следующая ситуация.
В одних случаях мы задали жесткое правило: карточки признавать дублями. В других строго определили: клиентов считать разными. Но большинство квадратов белые, потому что невозможно покрыть правилами все многообразие ситуаций.
Но буду честным: я бы не поставил зарплату на то, что Иваны Травины справа — разные. Опечатки в номерах встречаются постоянно: порядок цифр мог перепутать оператор, когда заполнял карточку клиента. Или сам Иван, когда оставлял заявку на кредит. Различие столь мало, что перед нами наверняка один клиент.
Что ж, исправим ситуацию: добавим жесткое правило, что карточки из примера справа мы считаем идентичными.

Принимаем волевое решение: считать клиентов одним человеком, если карточки различаются только порядком двух цифр в номерах телефонов
Тут и проявляется главная проблема подхода: на каждое несоответствие данных теперь понадобится свое правило: для опечаток, замен (например, «ул.» и «улица») и так далее. Причем все ситуации с расхождением данных не предусмотреть, их бесконечно много.
В одних случаях мы задали жесткое правило: карточки признавать дублями. В других строго определили: клиентов считать разными. Но большинство квадратов белые, потому что невозможно покрыть правилами все многообразие ситуаций.
К тому же правила жестко привязаны к данным. Если формат или характер данных однажды изменится — правила сломаются.
Дата-стюарды заметили, что абоненты одного из сотовых операторов часто ошибаются в телефонном коде. Например, при заполнении формы на сайте порядок цифр. Под опечатку в банке создали правило.
Через год у мобильного оператора сменили код, и все завязанные на этот код правила сломались.
Жесткие правила никуда не годятся. Даже не уверен, что их реально кто-то использует до сих пор. Но это и не важно: нам такой подход нужен как стартовая точка, худший из существующий вариантов.
Теперь можно двигаться дальше.
Вероятностная модель
Следующая идея, которая приходит в голову, — ввести скоринговый коэффициент «похожести». Это число показывает, насколько записи схожи. Если мы знаем, как его найти, остается выбрать порог и выше него считать карточки дубликатами.
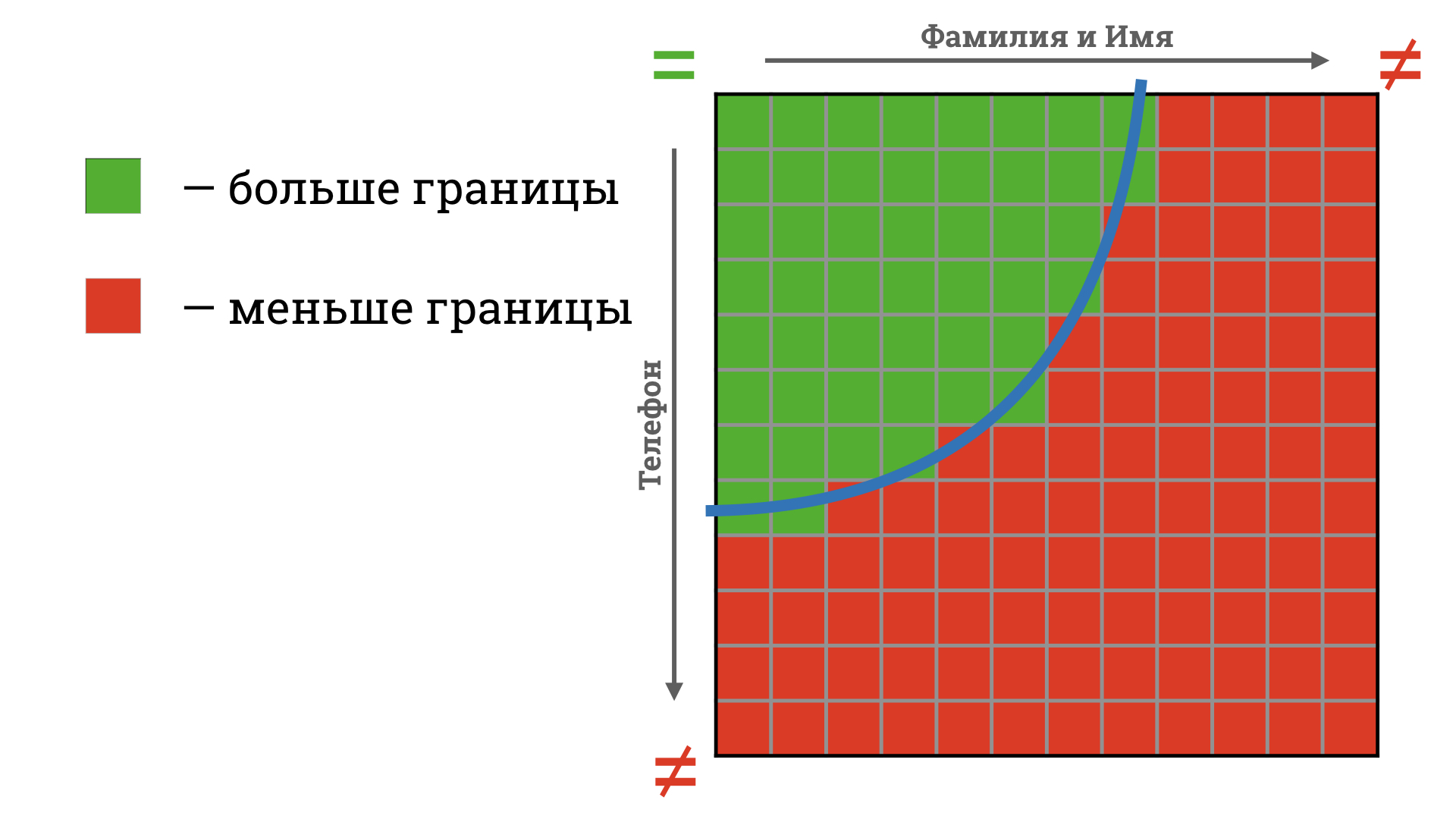
Выглядит логично, пока мы не сталкиваемся с ситуацией как на картинке ниже.

Изменение порядка цифр в номере телефона — вполне себе опечатка. Другая буква в фамилии — не факт. Речь может идти о совершенно другом человеке.
Вероятностный подход отлично учитывает количество отличий, но не обращает внимания на качество, контекст этих отличий. Поэтому мы не полагаемся на чистый скоринг при поиске дублей.
Когнитивный подход
Совместим идеи! Возьмем скоринговый коэффициент из вероятностного подхода и наложим на него бизнес-правила и контекст отличий. Правила выглядят примерно так.

В зависимости от контекста отличий меняется итоговое значение «похожести» записей. Теперь можно разделить ситуации, которые при предыдущем подходе набирали одинаковое количество баллов.

Если визуализировать такие правила, получим следующее.
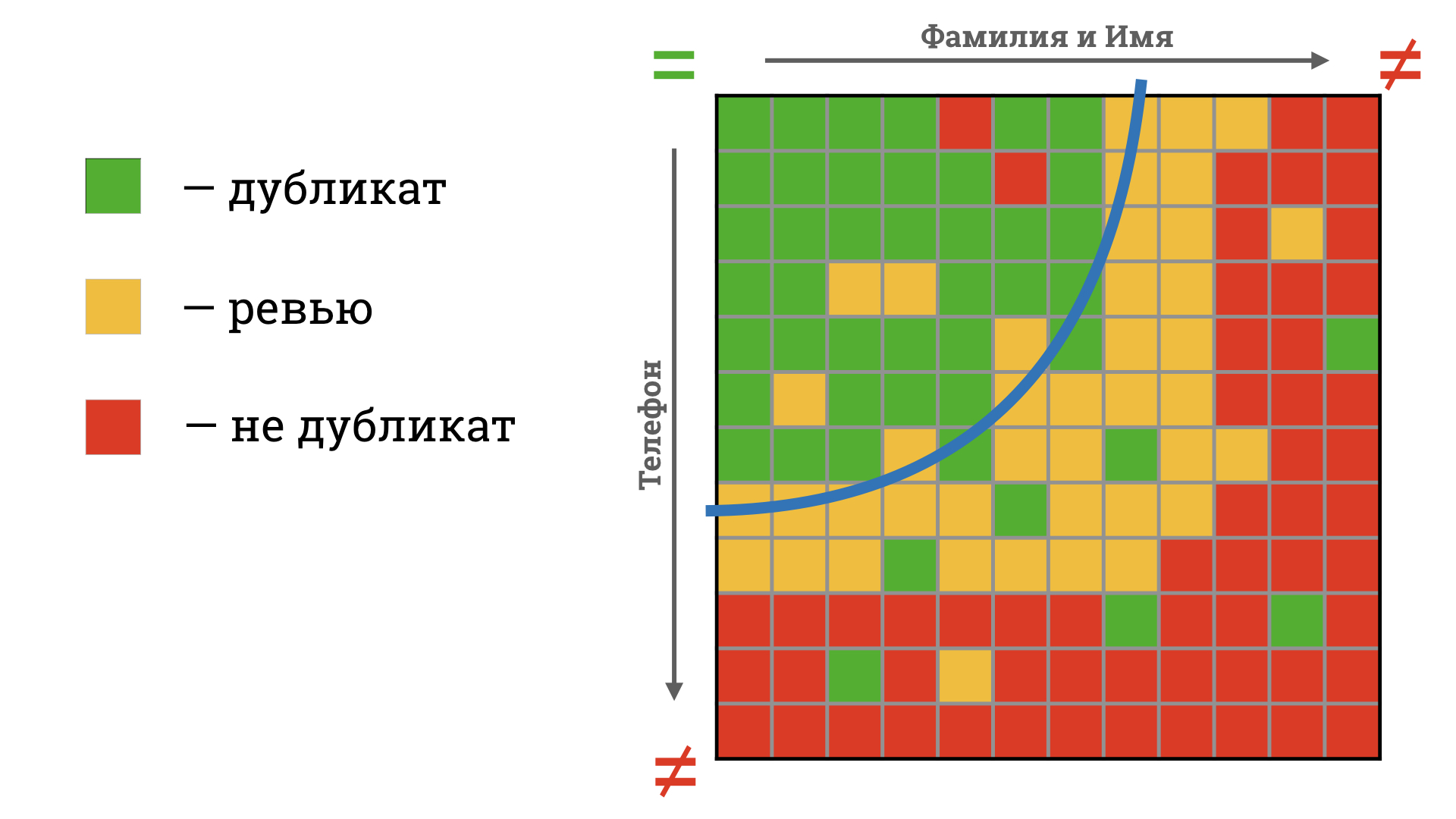
Красные и желтые квадратики выше синей линии — ложные дубликаты. По вероятностной модели мы бы ошибочно посчитали такие карточки дублями. Обратная ситуация с зелеными квадратиками ниже линии.
Такой идеей мы исправили слабые стороны и жесткого и вероятностного подходов:
- не нужно учитывать тысячи мелких отличий, потому что они считаются автоматически на основе скорингового покомпонентного коэффициента;
- бизнес-правила и контекст отличий мы учитываем с помощью жестких правил верхнего уровня. Их относительно немного.
Для четких правил нужен опыт
Для статьи мы взяли ситуацию, когда данных очень мало: только фамилия, имя и телефон. Если данных больше, правила становятся сложнее. Например, ниже — реальное правило поиска дубликатов в нашем «Едином клиенте».

Таких правил сотни, мы копили их десятки лет и выделяли специфичные для разных сфер бизнеса. Мы постоянно анализируем и улучшаем правила, а все изменения покрываем автотестами. В результате при внедрении «Единого клиента» нужно лишь тонко подстроить проверенный набор правил под конкретного заказчика. Поэтому HFLabs дает быстрый результат.
Пара слов о конструкторах правил
Порой нам говорят: вся эта история с правилами очень сложная. А «Единый клиент» — дорогой, потому что вы продаете его вместе со своей экспертизой и опытом в виде этих самых правил.
Мол, существует другой класс систем: красивые конструкторы с визуальный интерфейсом. Можно взять такой конструктор и относительно быстро накидать покомпонентные правила поиска дубликатов. Никакой «Единый клиент» не понадобится.
Поклонники таких продуктов утверждают, что бизнес сможет самостоятельно настроить правила поиска дублей. Вот же, все наглядно.
Спору нет, такая красота хороша на презентациях. Но в жизни этими красивыми стрелочками и фигурками придется рисовать те же самые сотни правил, которые у нас уже есть. Интерфейс не убережет от формализации правил и даже не облегчит задачу.
Наш опыт однозначно говорит: даже если конструктор очень красивый, бизнес не готов настраивать в нем сотни правил, тестировать их и поддерживать изменения. Это очень сложно.
Еще один «бонус» конструкторов — усложнение правил и настроек непропорционально сильно замедляет систему.
Продолжение цикла о теории CDI — «Что делать с гарантированными дублями».



